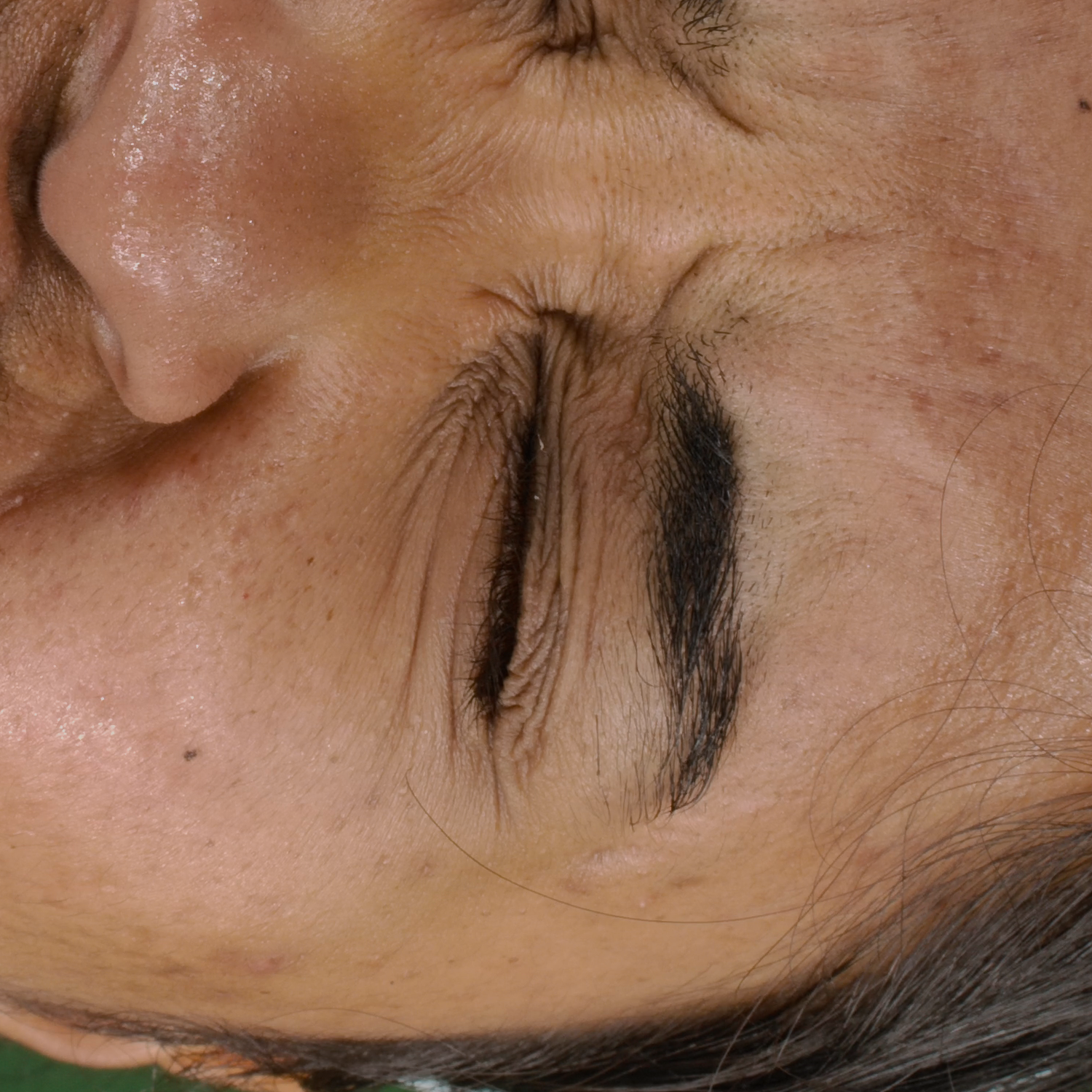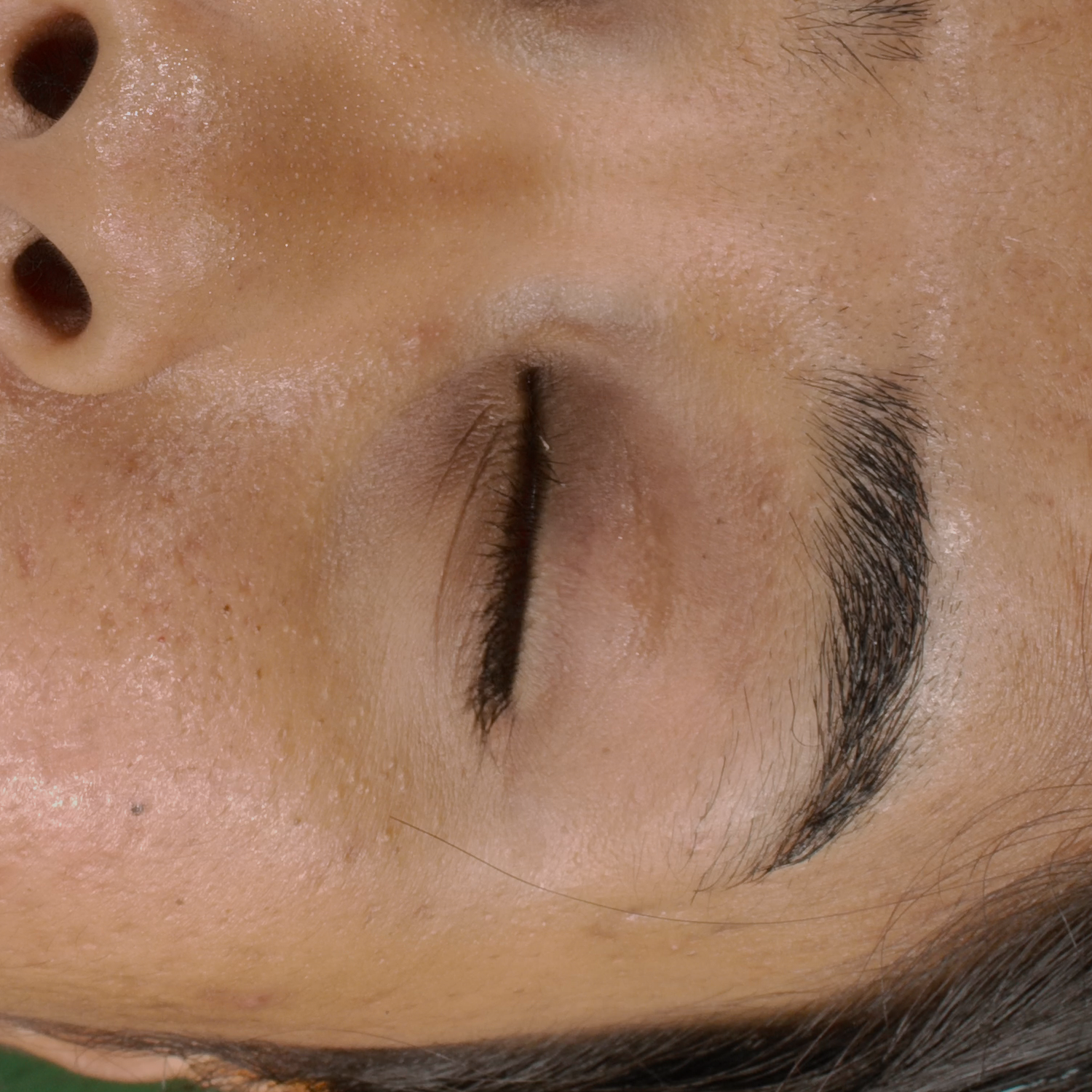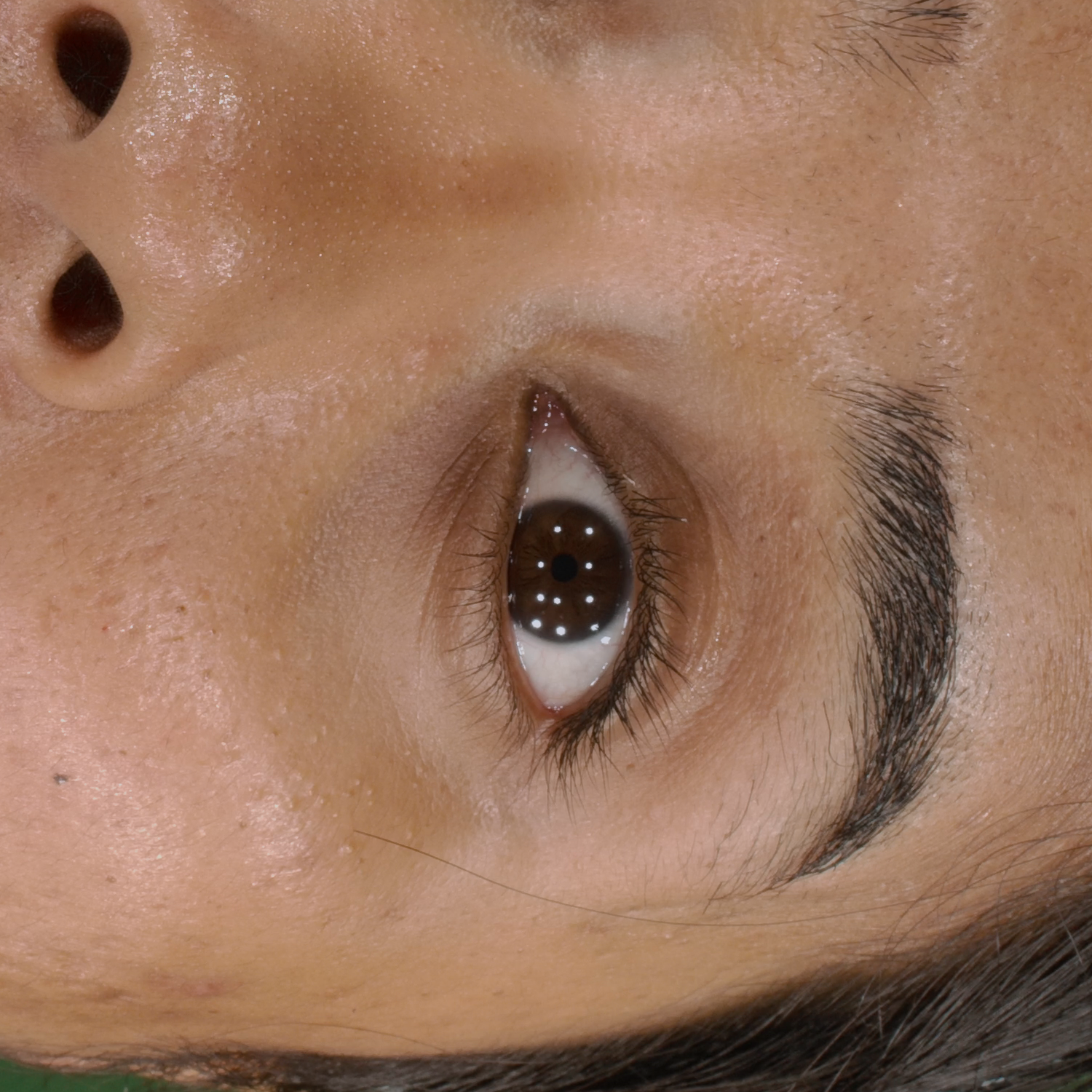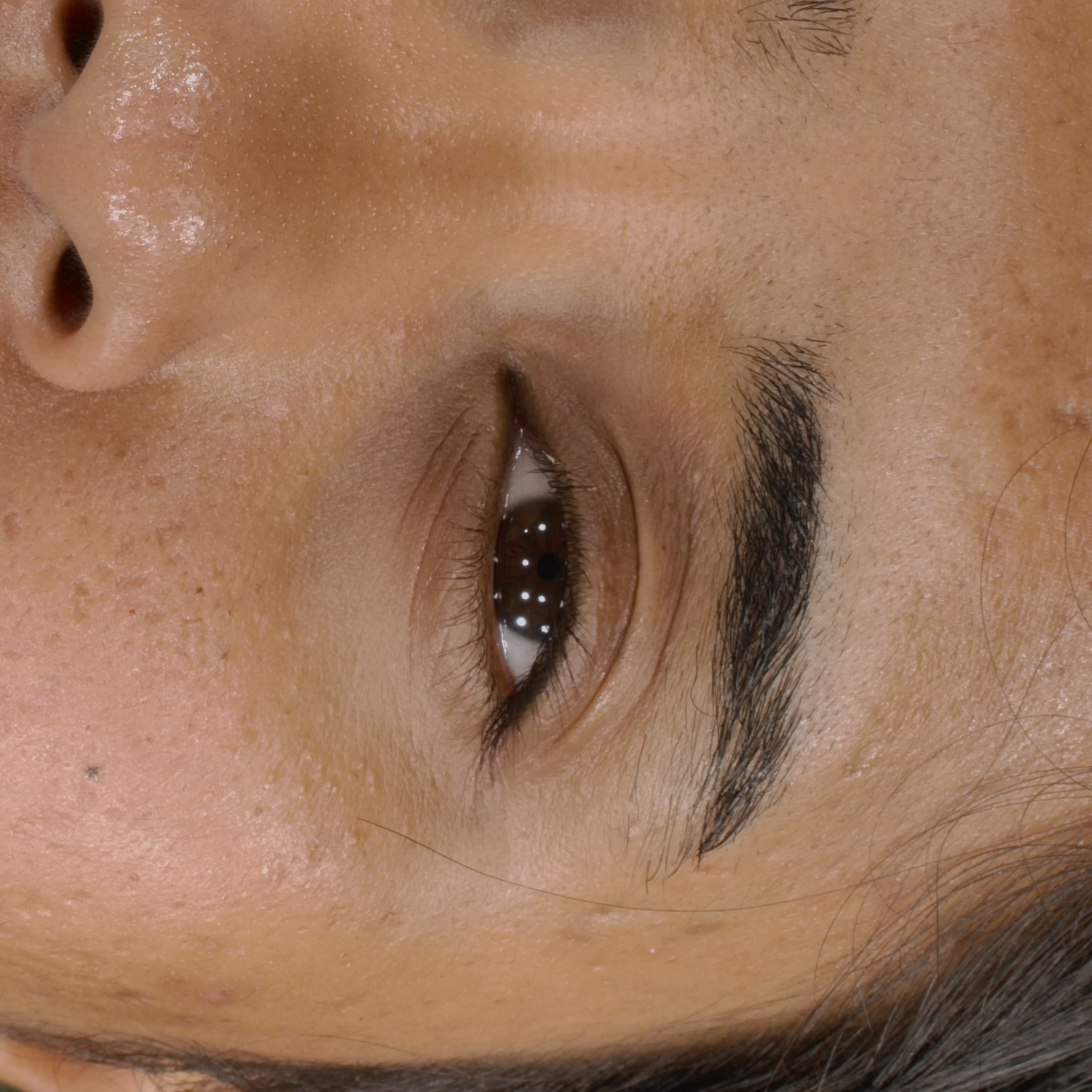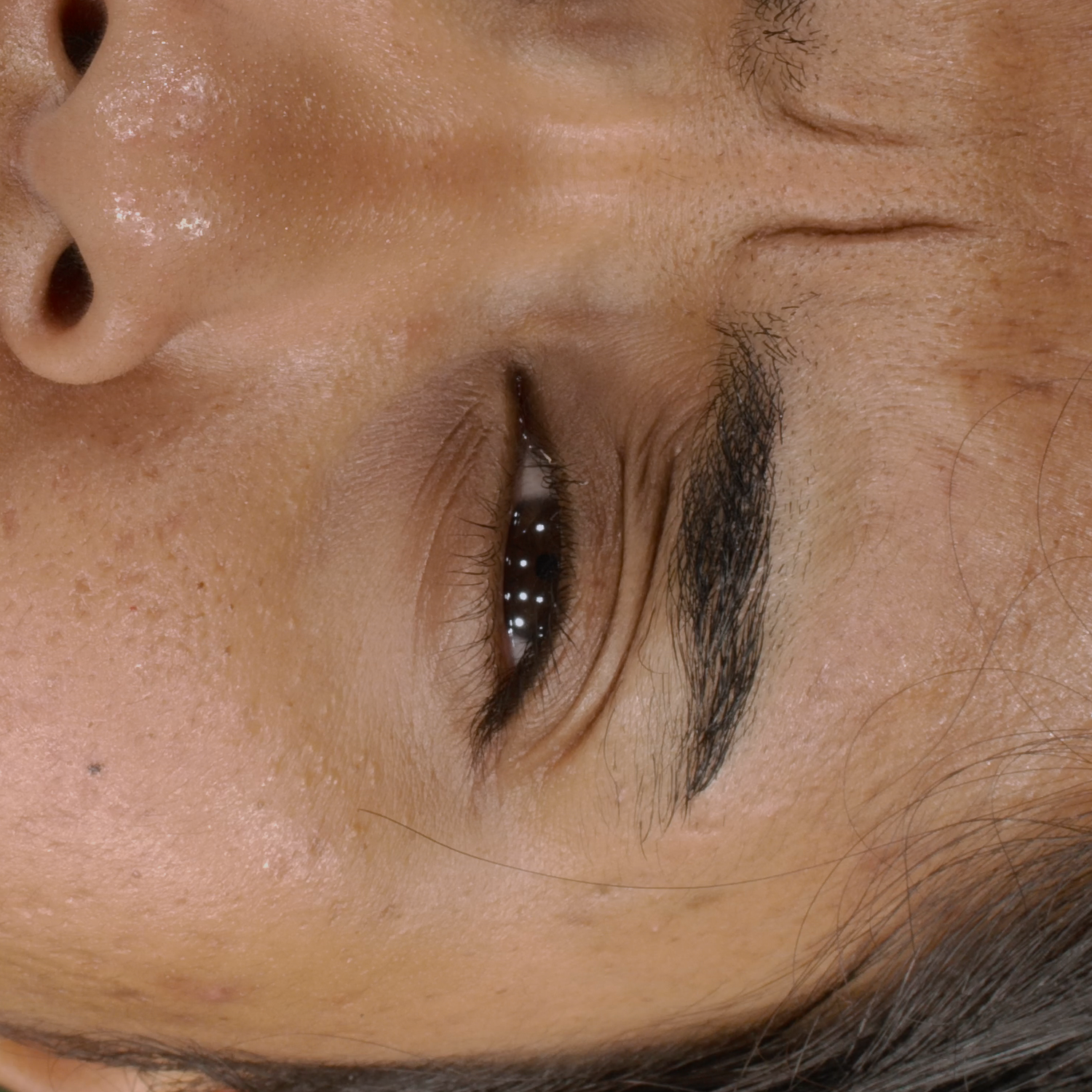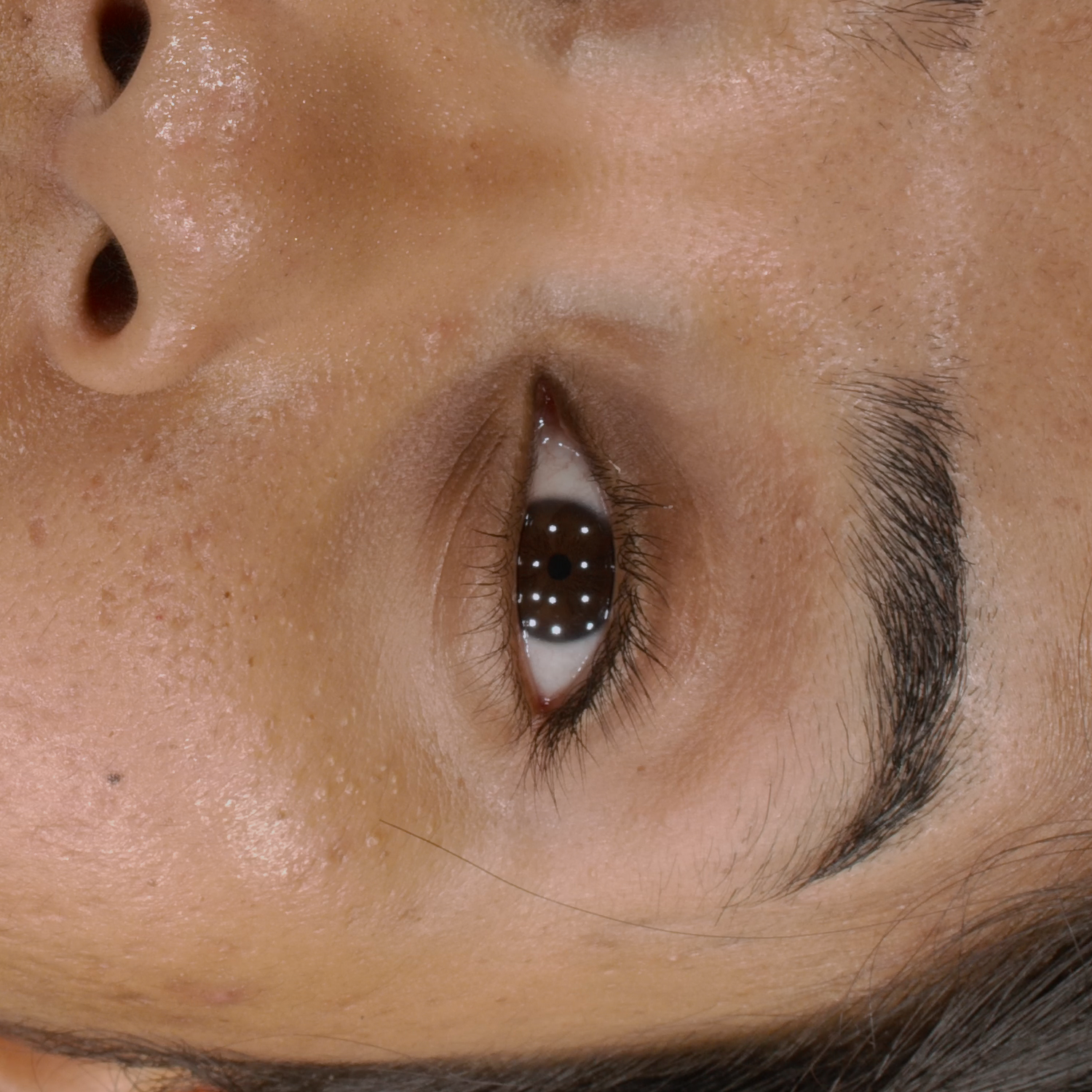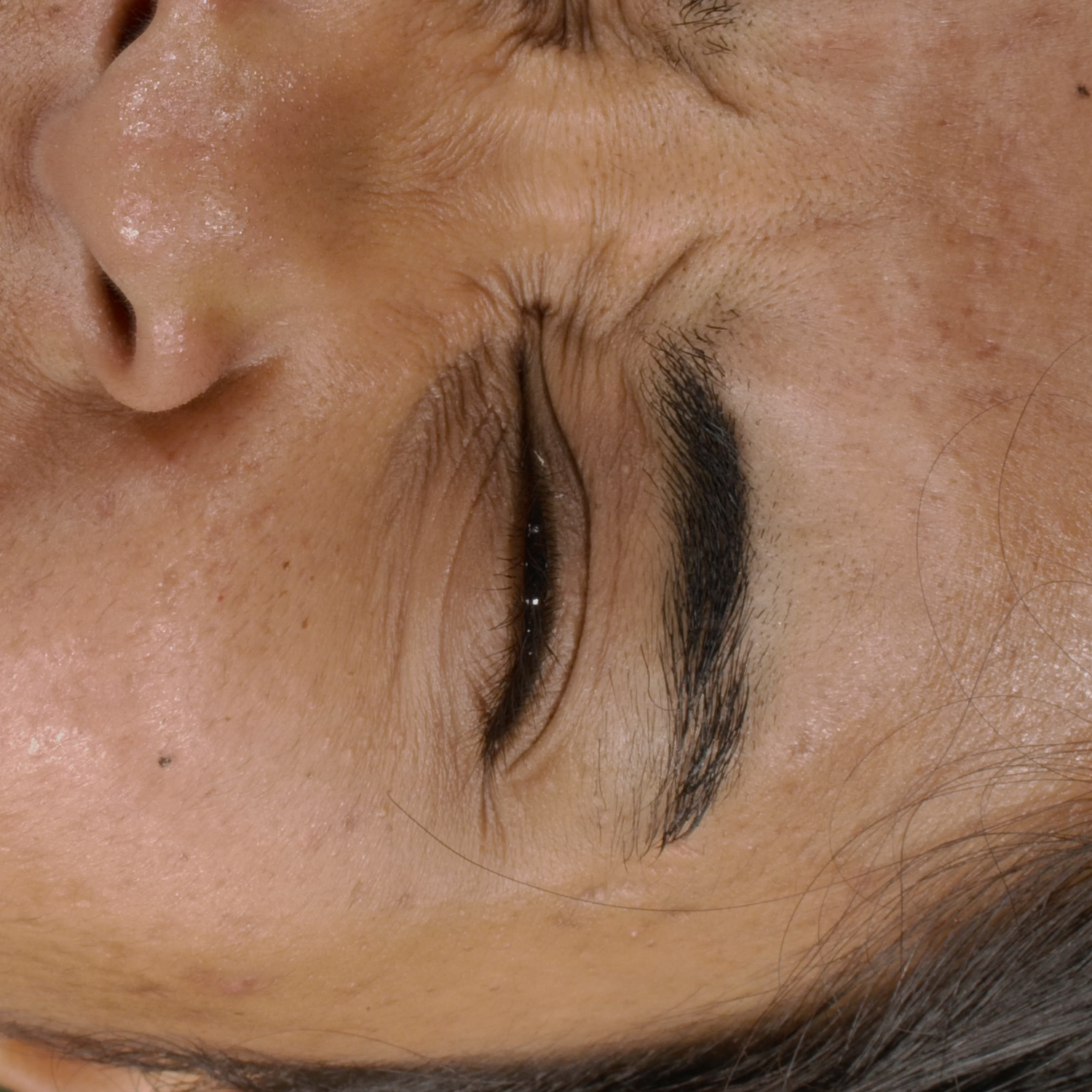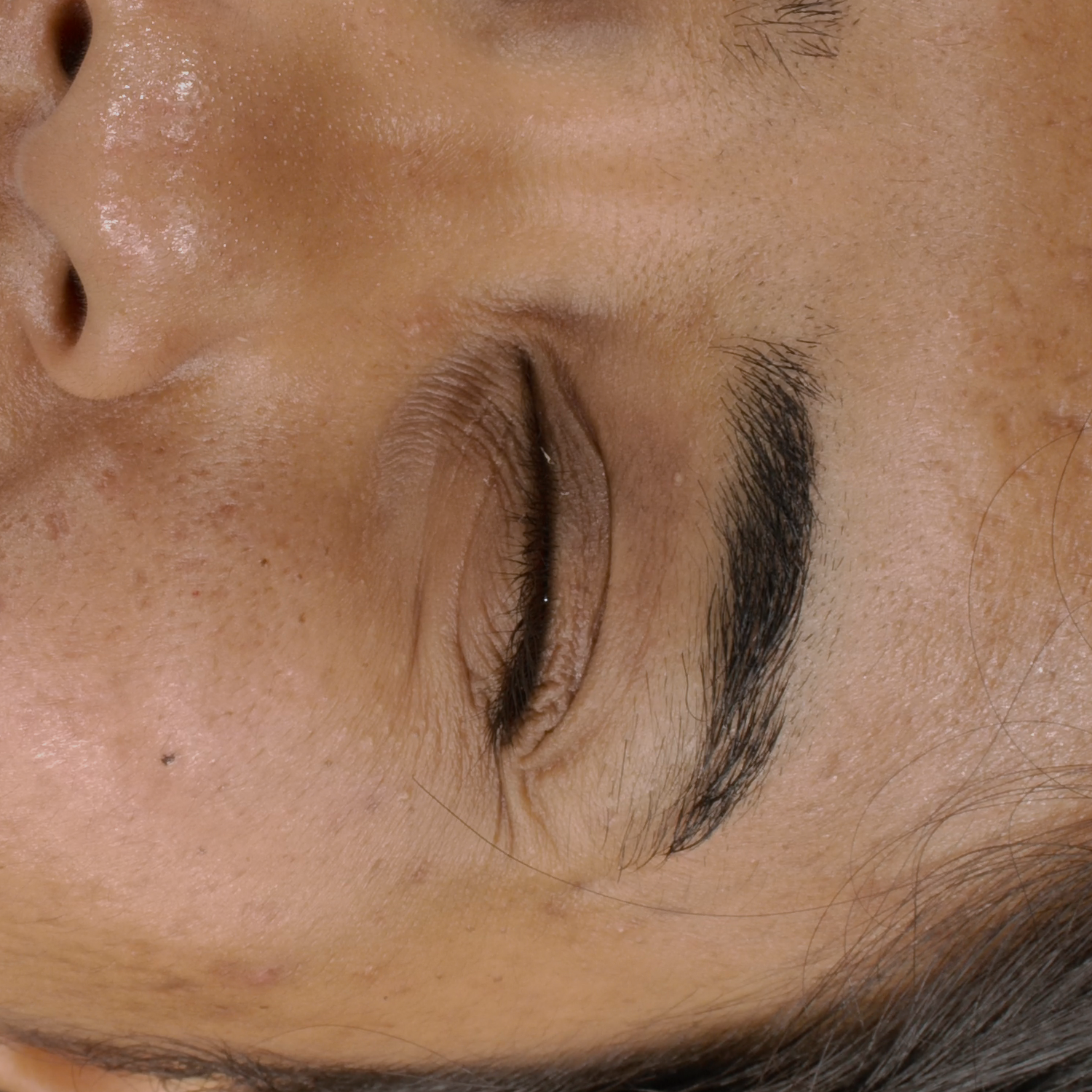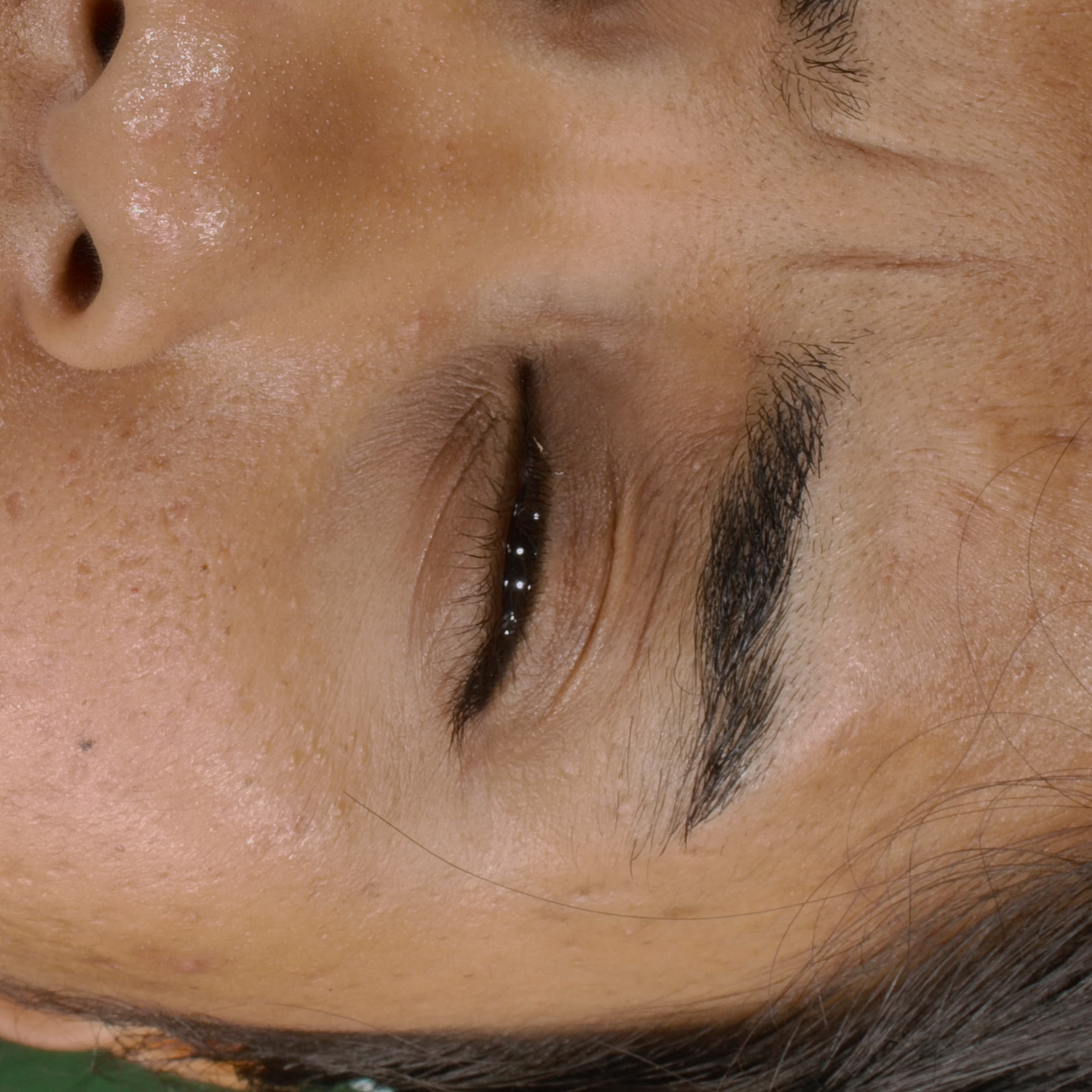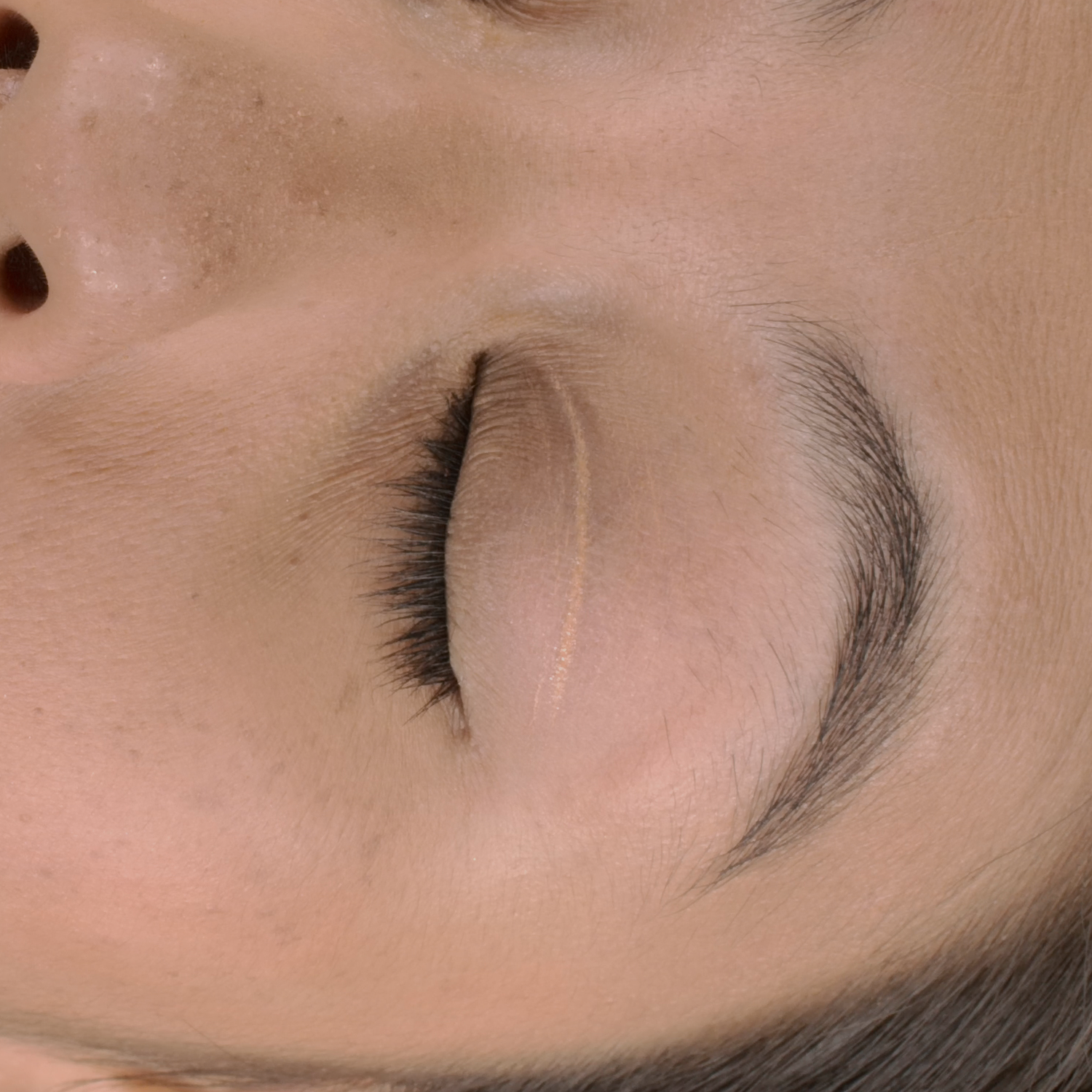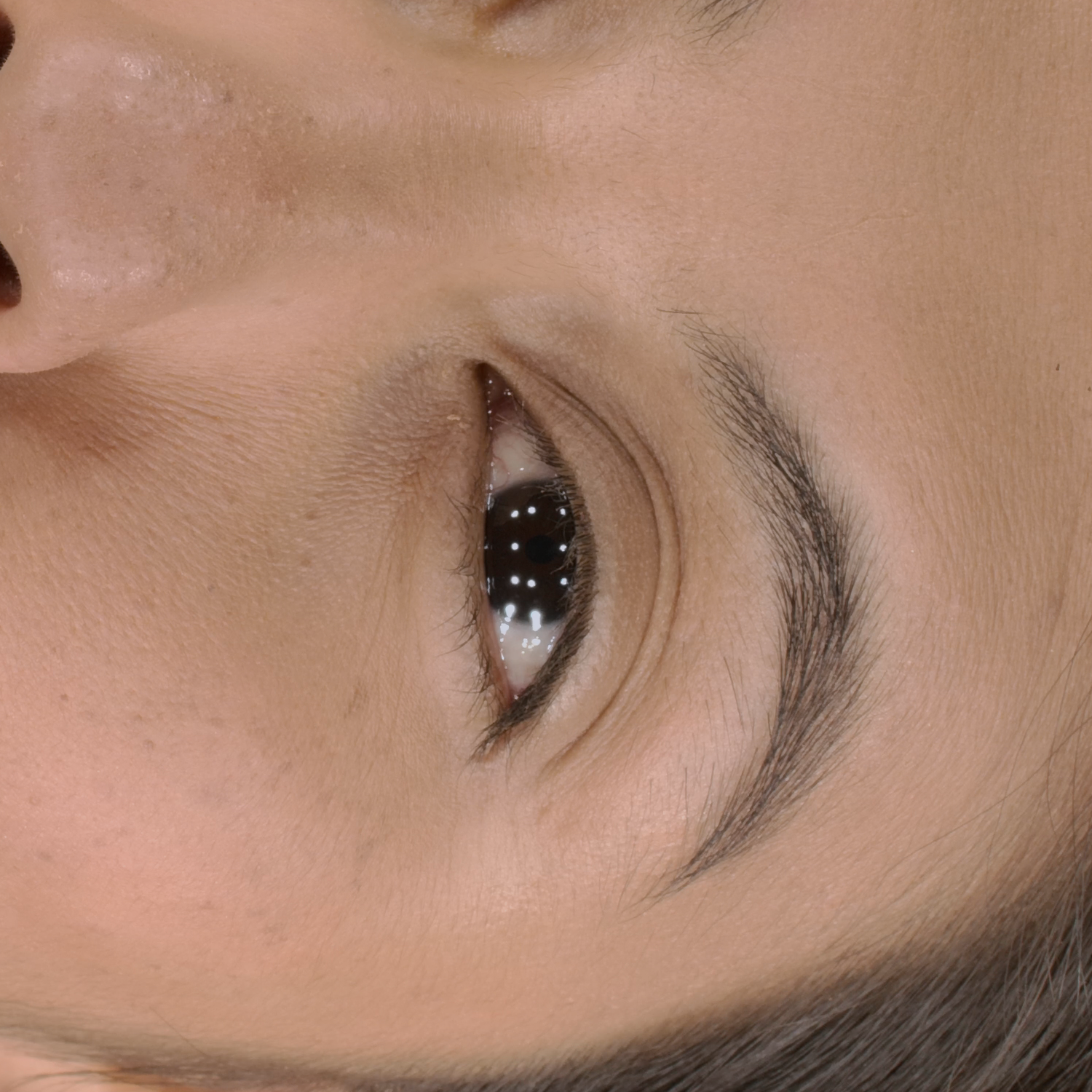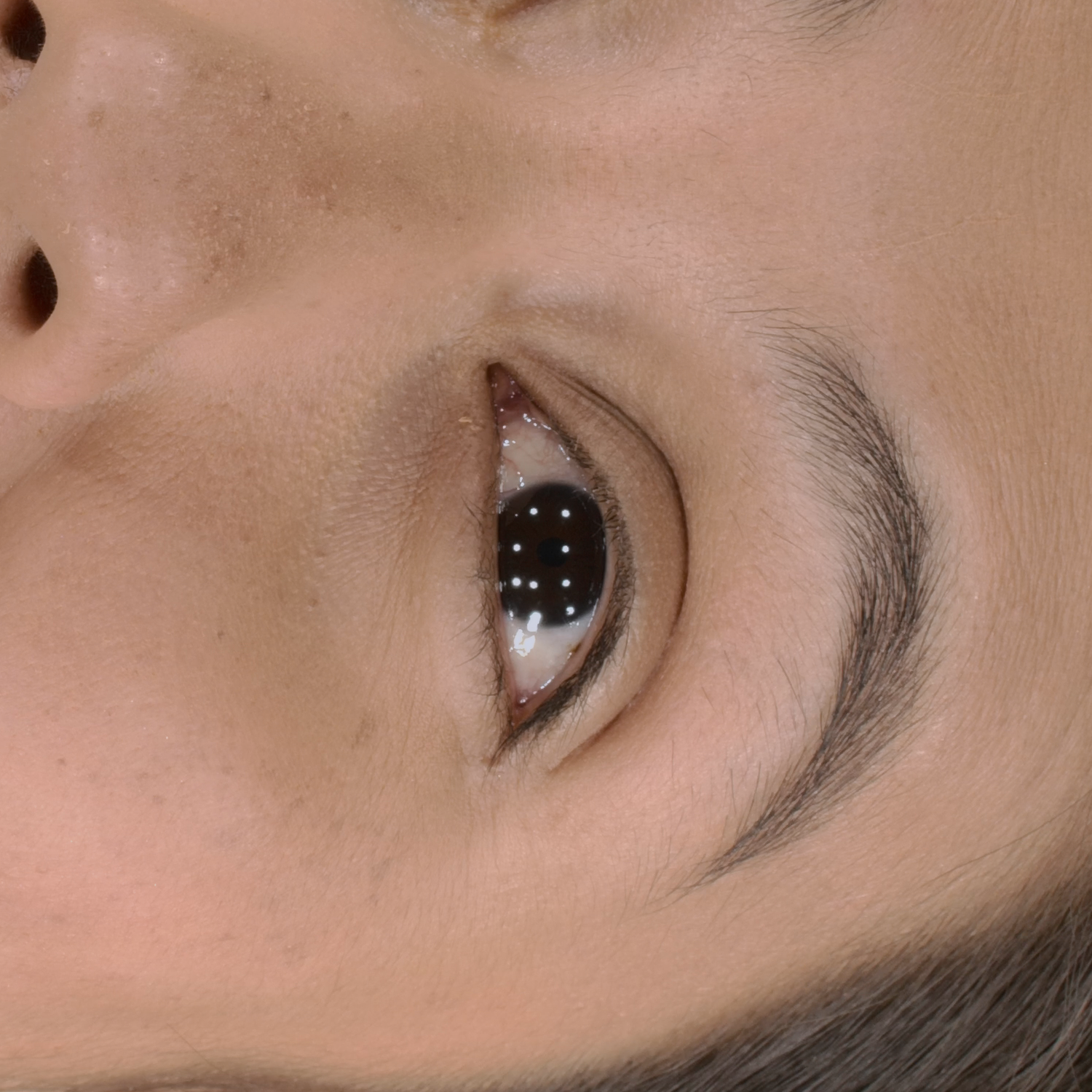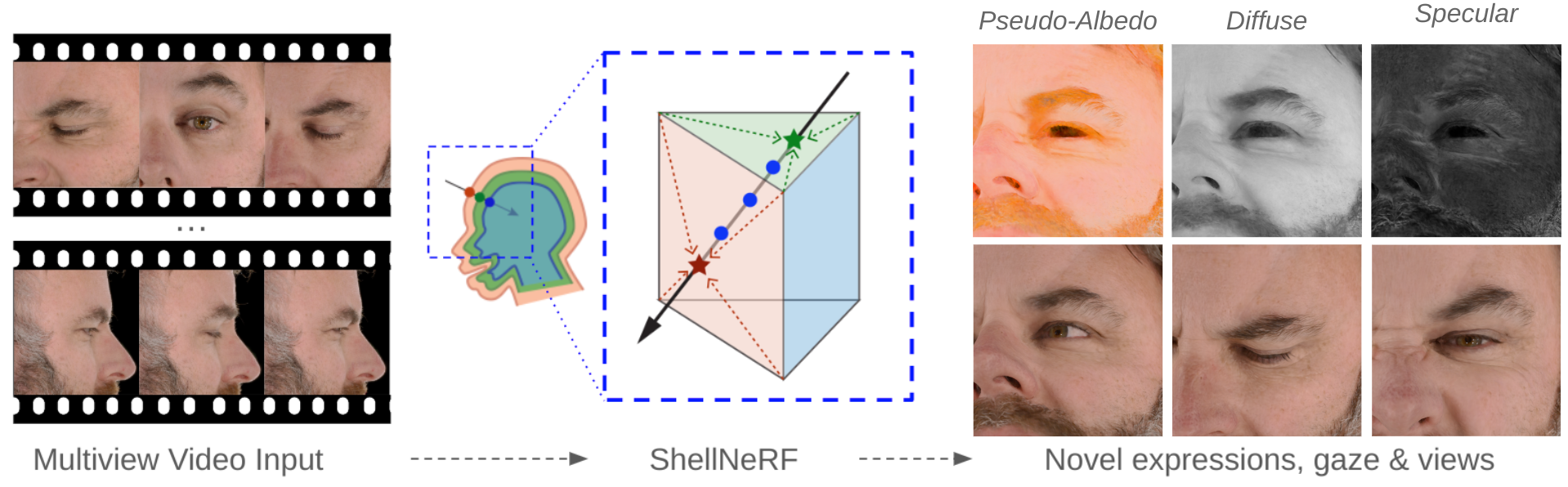
Novel View Synthesis
We can render the same scene from continuous camera views. Unlike other methods, we ensure multiview consistency and do not "hide" wrinkles and shadows beneath the skin surface. Nerface suffers from high instability and often diverges, as seen in the second subject